This is a sequel to my previous blog post where I discussed the fundamental theory of linear regression with gradient descent.
Here we’ll continue our study of gradient descent by implementing it in python.
To start, I’ll import the dependencies
import numpy as np
from pylab import *
%matplotlib inline
Recal that in simple one dimensional regression problems we are given a set of $x,y$ pairs from some unknown function $F(x)$ and are trying to fit some model $f(x,w)$ to best approximate the function $F$ generating the dataset, where $x$ is some $x_i$ from the set of input data and $w$ is a parameter vector we are trying to optimize.
For any actual $x_i$ in the input dataset, $\hat{y} = f(x_i, w)$ ought to be as close as possible to $F(x)=y_i$.
The code for implementing regression with gradient descent is actually remarkable simple. We’ll start by writing an abstract regression class and then subclass it for our specific choice of model and error function.
class AbstractRegression:
def __init__(self, xs, ys, w,alpha):
self.w = w
self.xs = xs
self.ys = ys
self.a = alpha
self.N = float(len(xs)) # The size of the dataset
def f(x,w): return
def r(yhat, ys, xs): return
def update(self):
# Updating weights with respect to error
self.w -= self.a*self.r()
The init method takes xs, the set of input $x_i$ input points, ys the set of $y=F(x_i)$, alpha the learning rate $\alpha$, w an initial parameter vector,
In addition, all subclasses must implement three functions:
fa function of the formf(x, w)wherexis some arbitrary $x$ value, andwis a parameter vector.ra function of the which returns a vector the same length aswwhereEthe actual error function, as in absolute distance, or mean squared error, etc. Note thatEis not used in the training but is useful to have handy in the class.
Now we shall subclass AbstractRegression using mean squared error as our error metric:
and a linear model of the form
In my previous post we derived the learning rates $r$ for such a linear model:
and
and update rule
With this settled, see how incredible simple it is to implement this powerful tool:
class LinearRegression(AbstractRegression):
def f(self, x,w):
return w[0]*x + w[1]
def r(self):
yhats = self.f(self.xs,self.w)
loss = yhats - self.ys
return np.array([
(2./self.N)*np.sum(loss*xs),
(2./self.N)*np.sum(loss)
])
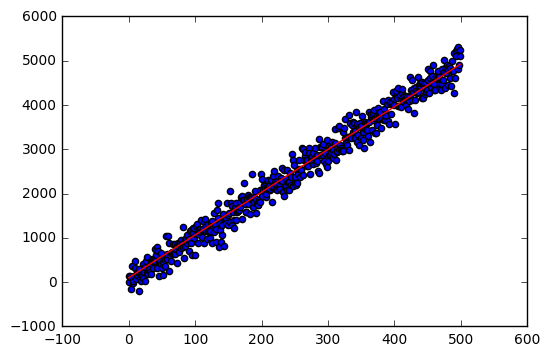
Now let’s test this out:
N = 500.
m = 10.
b = 10.
ws = np.array([100.,100.])
xs = np.arange(0,N)
ys = m*xs + b + np.random.randn(N)*200
regressor = LinearRegression(
xs, ys, ws,
0.0000001)
for i in range(10000):
regressor.update()
w= regressor.w
print w
yhat = xs * w[0] + w[1]
actual = scatter(xs, ys)
predicted = plot(xs, yhat, color='red')
[ 9.65885386 99.69371247]